CheckMag | Nincs GPU, nincs probléma. A saját LLM tárhelye végtelenül szórakoztatóbb, mint a nagy játékosok cenzúrázott ajánlatai, és meglepően jól működik.

Hogy valójában mi történik az adataiddal, amikor lekérdezel egy mesterséges intelligenciát, azt csak találgatni lehet, de bármi is történik vele, az már biztosan nem a tiéd.
A mellett kép és videógenerálás mellett, ha szívesen kísérletezne nagy nyelvi modellekkel (LLM), de nem szeretné átadni az adatait a nagyvállalatoknak, a saját nyelvi modellek üzemeltetése meglepően egyszerű, és számos előnnyel jár a nagy szereplőkkel szemben.
Elsősorban az, hogy bármit is akarsz vele csinálni, az összes adatod a te irányításod alatt marad, ami, ha nem akarod átadni az adataidat a Mechahitler, azonnali előny. Emellett nagyjából bármilyen modellt használhat, amit csak akar, legyen az Deepseek, Gemma2 vagy GPT, azzal a további előnnyel, hogy olyan verziókat használhat, amelyek nem korlátozzák a lekérdezések típusait.
A KoboldCPP egy könnyen használható, egyetlen futtatható AI szöveggeneráló eszköz, amelyet a GGUF és GGML nagy nyelvi modellek futtatására terveztek. Támogatja mind a GPU-t, mind a CPU-t, és képes speciális háttértárként működni az AI mesélés és a chatelés számára. A KoboldCPP letölthető a GitHubról: innen és elérhető Windows, Linux, Mac vagy Docker rendszerre.
A konténerben való tárolás triviálissá teszi, hogy az LLM-et a hálózat minden eszközéhez ki lehessen tenni, és a főbb platformokhoz, köztük az Unraid és a TrueNAS számára előre elkészített sablonok állnak rendelkezésre. Ugyanez más telepítésekkel is megvalósítható, amennyiben hozzáadja a szükséges szabályokat a tűzfalához.
Kezdő lépések
Miután eldöntötte, hogy melyik platformot választja, ki kell találnia, hogy milyen modellt használjon. Ölelő arc a legjobb hely, ahol modelleket kereshetsz, és ezeknek GGUF formátumban kell lenniük.
Ha D&D forgatókönyveket tervezel, akkor mindenképpen cenzúrázatlan modellt akarsz, különben az LLM végül nem hajlandó ártani a karaktereknek, és generálhat nemkívánatos eredményeket.
Egyes modellek, mint például a Deepseek és a Claude, hajlamosak "gondolkodni", ami alapvetően a lekérdezés teljes gondolatmenetét kiköpni. Ez rendben lehet, ha egy GPU végzi a nehéz munkát, de nélküle jelentősen lelassítja a folyamatot. Kísérleteznie kell a modellekkel, hogy megtalálja a számára megfelelőt, de Gemma2 egy jó kiindulópont.
Keresse meg a fájlok oldalát, és másolja ki a GGUF fájlra mutató URL-t. Sok modellnek többféle mérete van, ezért olyat kell választania, amelyik belefér a rendelkezésre álló RAM-jának korlátai közé.
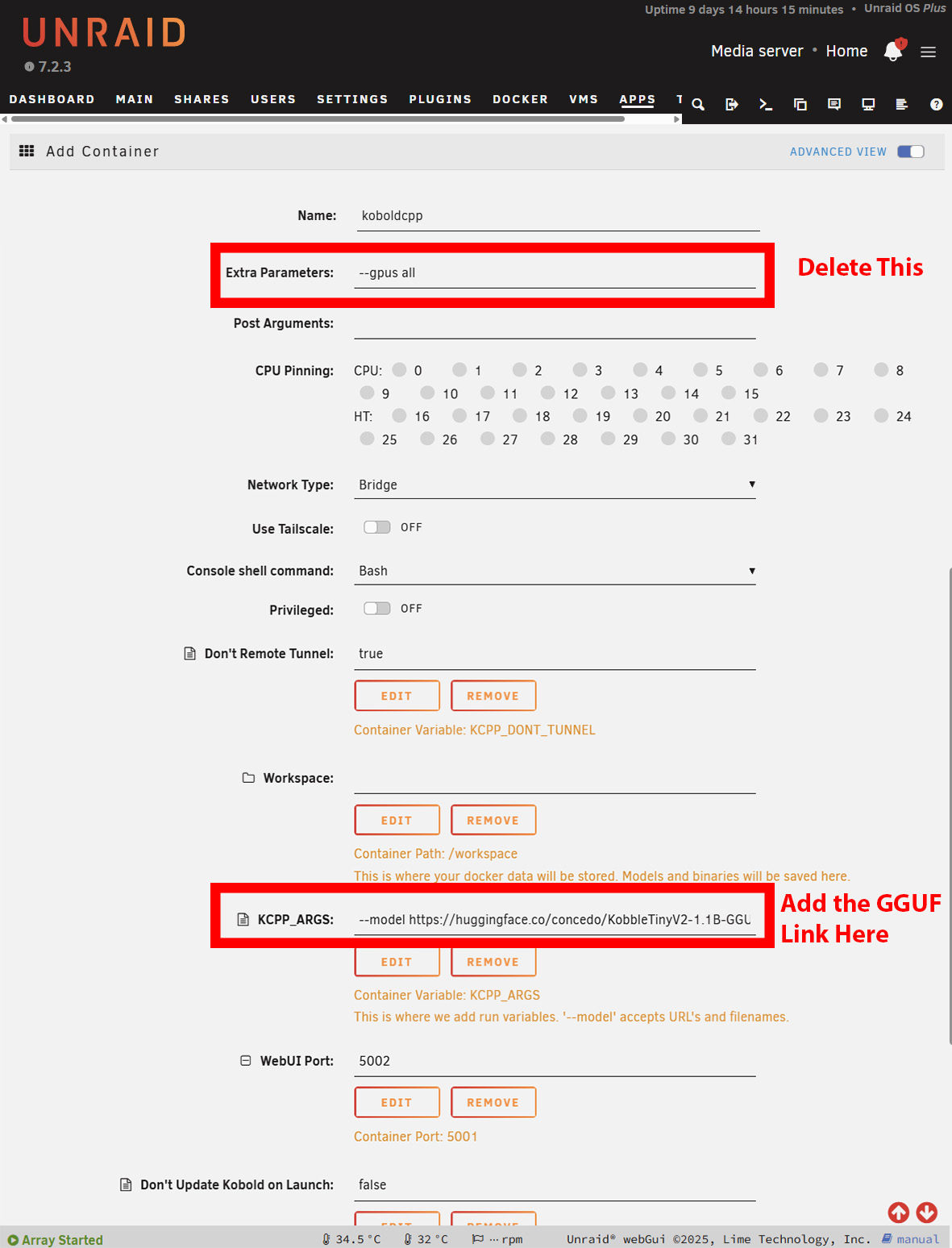
A telepítés Windows alatt nagyjából ugyanez. Azonban le kell töltenie a NoCUDA programot verziót, ha GPU nélkül használja. Az indítás eltarthat egy ideig, mivel a KoboldCPP letölti a modellt, mielőtt megjelenik a kezelőfelület. Windowson ez nyilvánvaló, de Unraid vagy TrueNAS rendszeren meg kell nyitni a naplókat, hogy lássuk a letöltés előrehaladását. Az Unraid rendszeren szükség lehet a növelésére a Docker-konténerek rendelkezésre álló tárhelyét, attól függően, hogy mekkora a választott modell.
A KoboldCPP 4 különböző kezelőfelületi módot kínál, beleértve az utasítást, a történetet, a csevegést és a kalandot.
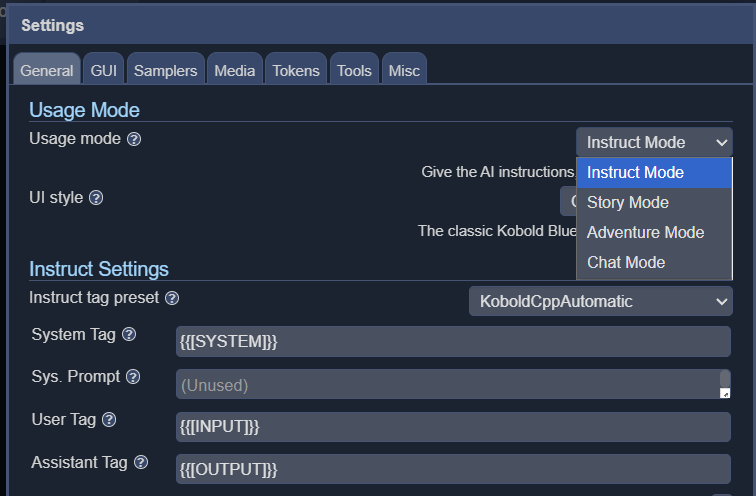
Bár nem a leggyorsabb, a szöveg generálása valamivel lassabb, mint az átlagos olvasási sebesség. Tökéletesen használható D&D forgatókönyvekhez, ha egy 16 magos AMD 5950x-en fut(kapható az Amazonon), és valószínűleg gyorsabban fog futni modernebb CPU-kon. Minél több magot tudsz rátenni, annál jobb, és egy tisztességes mennyiségű RAM lehetővé teszi a nagyobb modellek futtatását, bár 16 GB-mal is rendben leszel. A modell mérete és típusa szintén jelentős hatással lesz a generációs sebességre, és egy könnyebb modell választása jelentősen növelheti az általános sebességet.
Nyilvánvaló, hogy a legjobb élmény érdekében a nagy nyelvi modellek GPU-val történő futtatása optimális, azonban ha szeretné kipróbálni a sajátját, megkerülve a ChatGPT, Claude vagy Gemini korlátozásait vagy adatvédelmi vonatkozásait, nincs szüksége semmilyen díszes hardverre ahhoz, hogy elkezdje, és még így is tisztességes élményt kaphat.
Forrás(ok)

