A Grok 4 legyőzi a ChatGPT-t, hogy a legjobb nyilvános AI modellé váljon, miközben Elon Musk 300 dollár/hó prémium előfizetést reklámoz
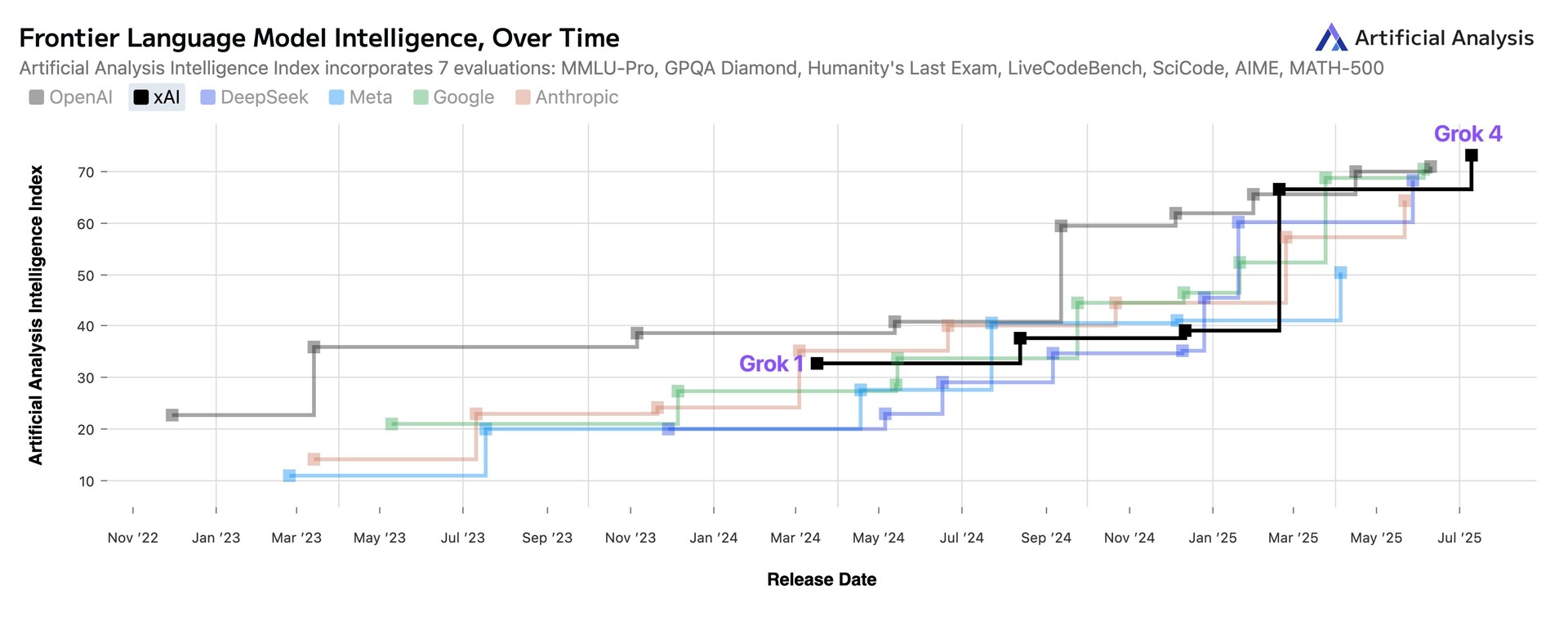
Kicsivel több mint két évvel a megjelenése után az xAI Grok lett a vezető AI nyelvi modell, megelőzve az OpenAI ChatGPT, a Google Gemini vagy a DeepSeek, valamint a Meta és az Anthropic modelleket. A Grok a jövő héten érkezik a Tesla autóiba, mondta Elon Musk.
Független, harmadik fél által végzett tesztek szerint az újonnan megjelent Grok 4 mostanra a nyilvános AI-modellek teljesítménytáblázatának élére került. A Grok 3 és a Grok 4 közötti 10x-es érvelésbeli javulás motorja az xAI által nyaktörő sebességgel épített AI számítási klaszterek voltak, amelyek a tervezett egymillió GPU-hoz vezető úton megduplázták a 200 000 GPU-t.
Az xAI csapata felvette a kapcsolatot az igényes ARC-AGI teljesítményteszt mögött álló emberekkel, és megkérte őket, hogy futtassák le a saját AI-tesztcsomagjukat, meglepő eredményekkel:
Először is, a tények: A Grok 4 jelenleg a legjobb teljesítményt nyújtó nyilvánosan elérhető modell az ARC-AGI-n. Ez még a Kaggle-en benyújtott, célzottan készített megoldásokat is felülmúlja. Másodszor: az ARC-AGI-2 nehéz a jelenlegi mesterséges intelligencia modellek számára. A jó pontszám eléréséhez a modelleknek egy mini-képességet kell megtanulniuk egy sor képzési példa alapján, majd ezt a képességet a teszteléskor be kell mutatniuk. A korábbi legjobb eredmény ~8% volt (az Opus 4 által). A 10% alatti értékek zajosak. A 15,9%-os eredmény áttöri ezt a zajhatárt, a Grok 4 nem nulla szintű folyékony intelligenciát mutat
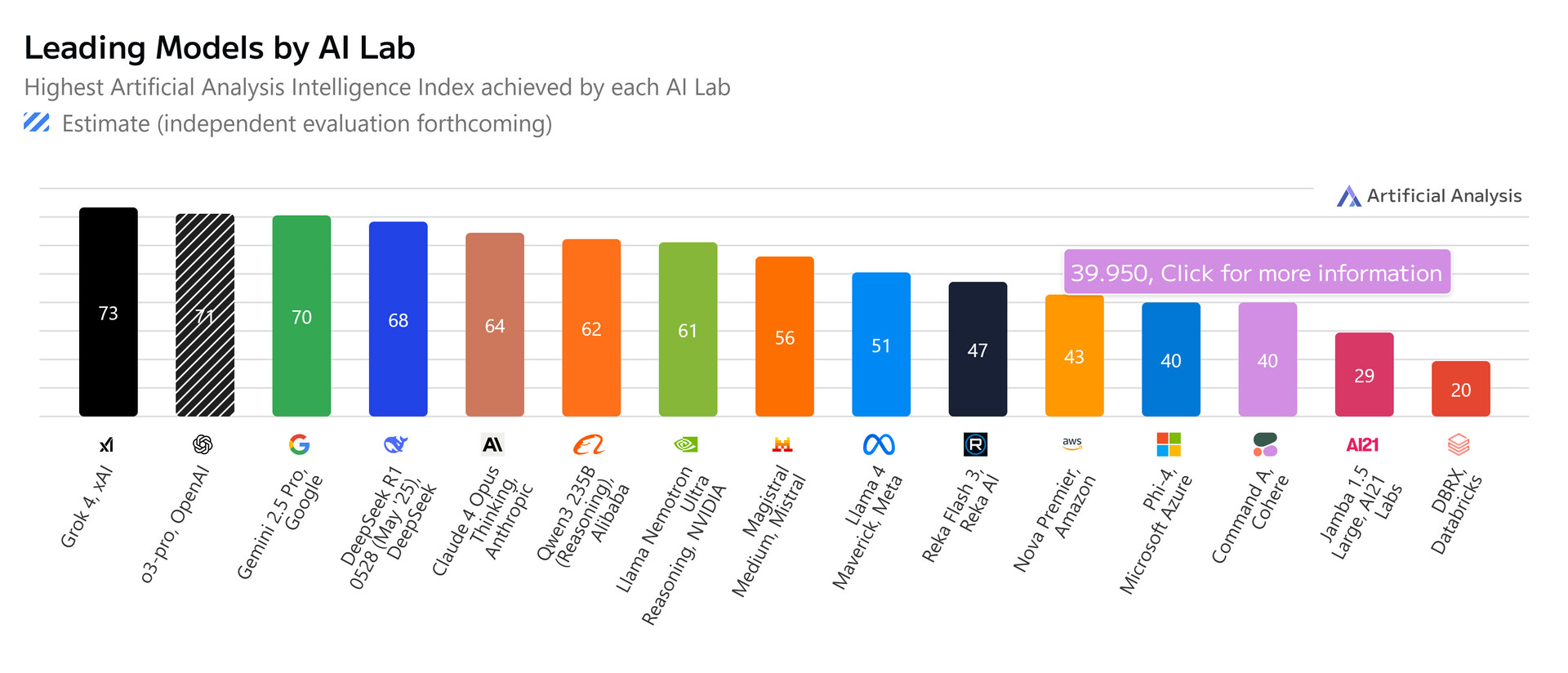
Egy másik független AI-tesztelő, az Artificial Analysis azt mondta, hogy"lefuttatta a teljes benchmark-csomagunkat, és a Grok 4 73-as Artificial Analysis Intelligence Indexet ért el, megelőzve az OpenAI o3 70-es, a Google Gemini 2.5 Pro 70-es, az Anthropic Claude 4 Opus 64-es és a DeepSeek R1 0528 68-as értékét"
Elon Musk szerint a Grok 4 bemutatójának bemutatóján az xAI modellje most okosabb, mint az összes végzős diák minden tudományágban együttvéve. A Tesla vezérigazgatója a rá jellemző, égbekiáltóan nagyképű hangnemben azt állította, hogy a Grok 4 képes lesz olyan "új technológiák" felfedezésére, mint pl gyógyszerek vagy mérnöki áttöréseket.
Mindazonáltal elismerte, hogy a Grok a következő egy hónapban még mindig rossz lesz a képfelismerésben, és kitért a közelmúltban a felsőbbrendűségi válaszok vitájára azzal, hogy"amikor a Grok nagyot hibázik, az általában valami ostobaság miatt van, amit mi csináltunk, például egy rossz rendszerkiáltás, vagy hogy túl nagy súlyt helyezünk az elfogult forrásokra"
Musknak a Grok 4-et kell pumpálnia, mivel az xAI-ja most először vezet be fizetős prémium szintet. SuperGrok Heavy néven 300 dollár/hónapról indul, és tartalmazza azt, ami a 30 dollár/hónapos SuperGrok tierben van, amely kezdeti hozzáférést biztosít a Grok 4-hez, plusz hozzáférést a Grok 4 Heavy platformhoz, amely magasabb díjszabási korlátokat és korai hozzáférést biztosít az új funkciókhoz.
A Grok 3 továbbra is ingyenesen használható marad a nagyközönség számára, míg minden X Premium+ előfizető a SuperGrok szintjén a Grok 4-hez való hozzáférést is tartalmazza.