Egy meglepő nyelv veri az angolt és a kínait a LLM teszteken, egy új tudományos tanulmány alapján
Egy új többnyelvű tanulmány, amely azt vizsgálja, hogy a nagy nyelvi modellek hogyan kezelik a hosszú dokumentumokat, váratlan információval szolgált: A legnagyobb pontosságot nem az angol vagy a kínai, hanem a lengyel nyelv mutatja, amikor a kontextusablakok 64 000 tokenre vagy annál nagyobbra nyúlnak. Az eredmények a OneRuler benchmarkból származnak, amelyet egy COLM 2025 dokumentumban mutattak be, amely 26 nyelvet tesztelt a keresési és az aggregációs feladatokban.
A kutatók összehasonlították a modell pontosságát különböző kontextushosszúságok esetén, és egyértelmű változást tapasztaltak, amint a szekvenciák hosszabbak lettek. Az eredménytáblázat szerint (a 6. oldalon) a lengyel vezet az összes nyelv között, 88%-os átlagos pontossággal a hosszú kontextusméreteknél. Az angol a hatodik helyre esik vissza, a kínai pedig az utolsó négy között szerepel.
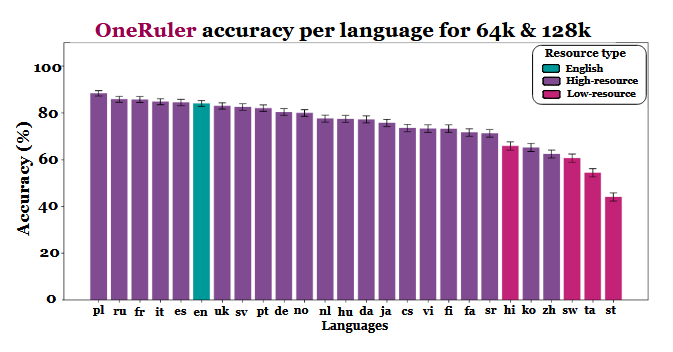
A tanulmány arra utal, hogy az eltérés inkább a tokenizálás hatékonyságához és a szkript-alapú különbségekhez, mint egyszerűen a képzési adatmennyiséghez köthető. A latin alapú írásmódot használó nyelvek - például a lengyel, a francia és a spanyol - következetesen jobban teljesítettek, mint a logográfiai vagy abugida írásmódot használó nyelvek. A kínai, a koreai, a tamil és más nyelvek még rövidebb kontextusok esetén is csak mérsékelt pontosságot mutattak (és pontosságuk tovább romlott, ahogy a szekvenciák hosszabbak lettek). A várt rangsornak ez a 180 fokos fordulat azért érdekes, mert a legtöbb széles körben alkalmazott LLM-et elsősorban angol nyelvű adathalmazokon képezték ki. A tanulmány eredményei mégis azt mutatják, hogy amint a modelleknek hosszú dokumentumok mélyén eltemetett információkat kell keresniük, felidézniük vagy összefoglalniuk, a nyelv strukturális szempontjai előnyt élveznek az adathalmazok elterjedtségével szemben.
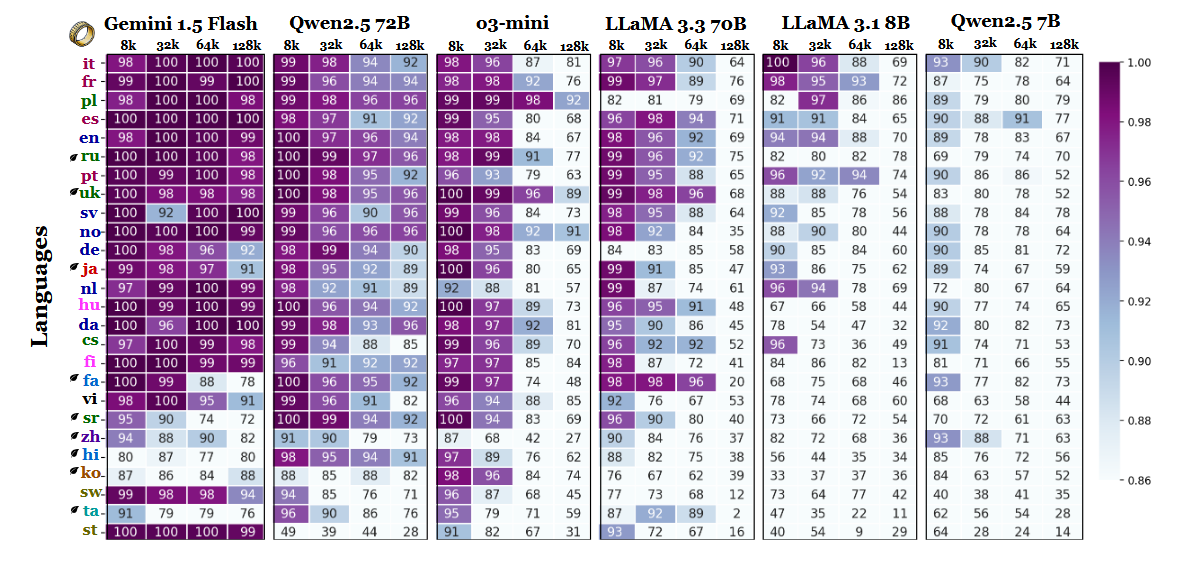
A benchmark egyéb eredményei is alátámasztják ezt az értelmezést. A legerősebb és leggyengébb nyelvek közötti teljesítménykülönbség a kontextus bővülésével meredeken nő - a 8 000 tokenre vonatkozó 11%-ról 128 000 tokenre vonatkozó 34%-ra. A tanulmány egy másik részlete azt mutatja, hogy ezek a tesztek mennyire érzékenyek lehetnek a kis utasításváltozásokra. Például, ha a modellnek egyszerűen megengedjük, hogy a célszöveg hiányában "nincs" választ adjon, az angol nyelvben a pontosság 32%-kal csökkent 128 000 token esetén, amint az a 2. oldalon látható.
Bár a benchmark a modellcsaládokat is összehasonlítja, az eredmények arra utalnak, hogy a hosszú kontextusú értékelés nem támaszkodhat kizárólag az angol nyelvű tesztelésre, és hogy a nyelvek közötti teljesítmény általánosítása félrevezető lehet, ha figyelmen kívül hagyjuk a szkript és a tokenizáció hatásait. Ahogy a kontextusablakok egyre nagyobbak lesznek, a nyelvi különbségek egyre fontosabbá válnak, nem pedig kevésbé - és az angol nyelv dominanciája az LLM benchmarkokban már nem biztos, hogy reprezentatív, amint a szekvenciahosszok a tízezres tartományba emelkednek.
Forrás(ok)
Egyetlen vonalzóval mérni mindet: Többnyelvű, hosszú szövegkörnyezetű nyelvi modellek összehasonlító mérése a COLM 2025-ös konferencián
Kiemelt kép: Zulfugar Karimov on Unsplash

