A Samsung bevezeti a TRUEBench-et az AI termelékenységének valós munkaforgatókönyvekben történő tesztelésére
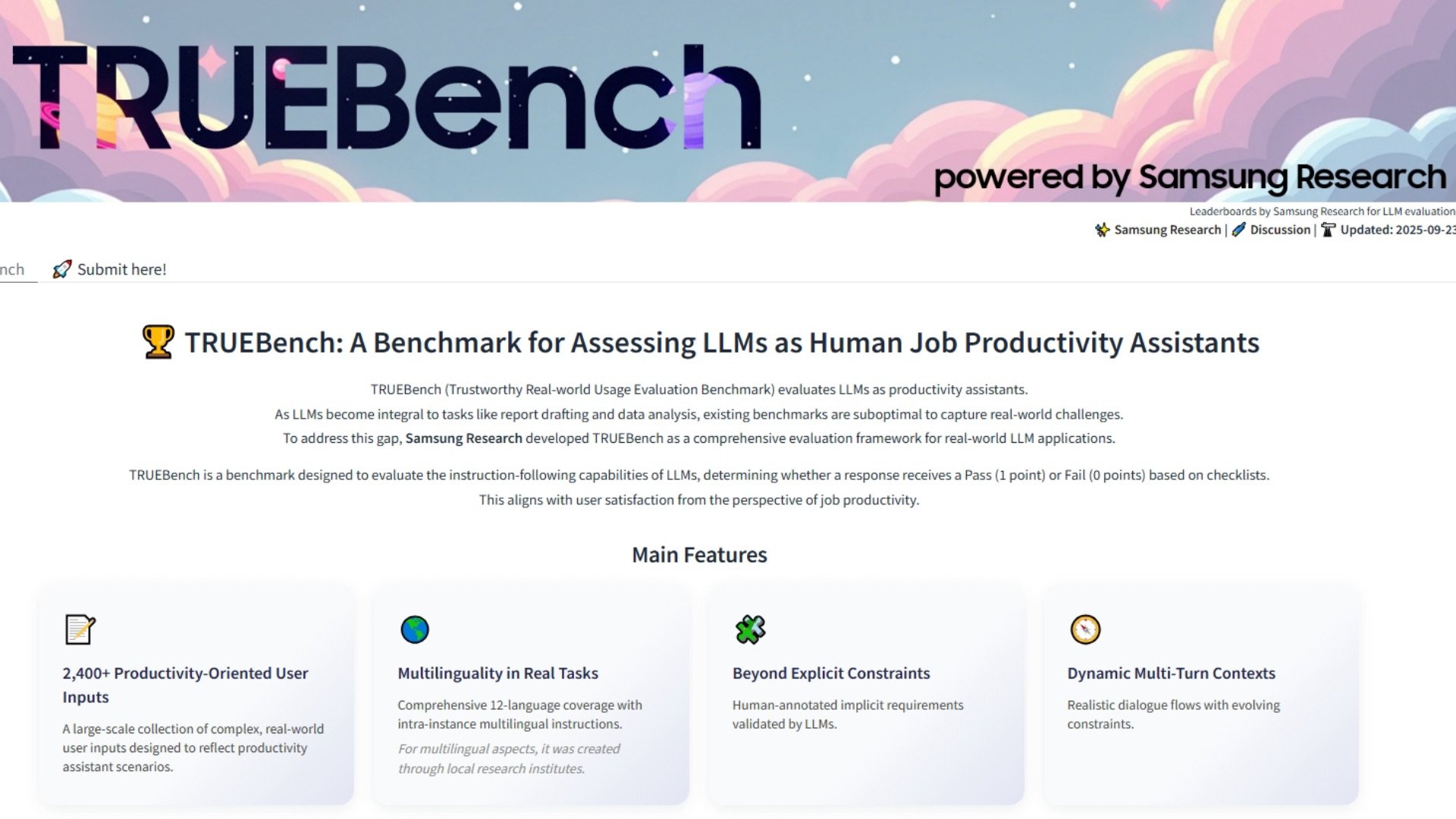
AI a benchmarkok már régóta küzdenek azzal, hogy megragadják, mit is csinálnak valójában az emberek ezekkel a rendszerekkel. A legtöbb teszt még mindig kizárólag angol nyelvű kérdés-felelet feladatokra összpontosít, amelyek papíron rendezettnek tűnnek, de nem tükrözik a napi munka során végzett tevékenységek sokféleségét. A Samsung most indította el https://news.samsung.com/global/samsung-introduces-truebench-a-benchmark-for-real-world-ai-productivityTRUEBench, a Trustworthy Real-world Usage Evaluation Benchmark rövidítése, hogy az AI teljesítményét olyan módon mérje, amely közelebb áll a valódi irodai feladatokhoz.
A TRUEBench túllép az egyszerű kvízkérdéseken vagy az egyszemélyes üzenetváltásokon, és a modelleket dokumentumösszefoglaláson, tizenkét nyelvre történő fordításon, adatelemzésen és többlépcsős utasításokon futtatja, amelyekhez az AI-nak kontextust kell fenntartania. A Samsung 2485 tesztkészletet fejlesztett ki tíz kategóriában és 46 alkategóriában, a bemenetek száma a maroknyi karaktertől a több mint húszezerig terjedt. A cél az, hogy a gyors parancsoktól a hosszú üzleti jelentésekig mindent szimuláljanak.
Paul (Kyungwhoon) Cheun, a Samsung Electronics DX divíziójának technológiai igazgatója és a Samsung Research vezetője elmondta: "A Samsung Research mély szakértelemmel és versenyelőnnyel rendelkezik a valós AI-tapasztalatok révén. Arra számítunk, hogy a TRUEBench értékelési szabványokat állít fel a termelékenység terén, és megszilárdítja a Samsung technológiai vezető szerepét"."
Ahhoz, hogy egy modell megfeleljen, a tesztben előírt minden feltételnek meg kell felelnie, beleértve az implicit feltételeket is, amelyek azt tükrözik, amit egy ésszerűen gondolkodó személy akkor is elvárna, ha ezek a feltételek nincsenek pontosan megfogalmazva. Ez a mindent vagy semmit módszer kevésbé megbocsátóvá teszi az eredményeket, de közelebb is hozza őket ahhoz, ahogyan Ön döntené el, hogy egy kimenet valóban hasznos-e. A Samsung az emberi input és a mesterséges intelligencia ellenőrzésének kombinálásával hozta létre a szabályokat. Emberi kommentátorok fogalmazták meg a kezdeti feltételeket, az AI jelezte az ellentmondásokat vagy ellentmondásokat, majd az emberek újra finomították a keretrendszert, mielőtt rögzítették azt. A véglegesítés után az értékelés automatizált mesterséges intelligencia-pontozással méretarányosan futtatható volt.
Samsung az adathalmazt, a ranglistákat és a kimeneti statisztikákat is nyilvánosságra hozta a Hugging Face-en keresztül. Akár öt modellt is közvetlenül összehasonlíthat, és megnézheti, hogyan állnak egymás mellett az eredményeik. Az átláthatóság ilyen szintje lehetővé teszi, hogy a fejlesztők, kutatók és felhasználók megvizsgálják a benchmarkot, és ne csak a Samsung állításaiban bízzanak.
A benchmark azonban nem tökéletes, mivel a szabálymeghatározás mindig tartalmaz bizonyos fokú torzítást, és a teljes siker minden feltételre való teljesítésének megkövetelése azt jelenti, hogy a részleges, de még mindig hasznos válaszok kudarcnak számítanak. A nyelvi támogatás messzebbre megy, mint a legtöbb létező teszt, de a teljesítmény elkerülhetetlenül eltérő lesz, különösen azokon a nyelveken, ahol kevés a képzési adat. A tesztkészlet az általános üzleti feladatok felé hajlik, így az olyan speciális területek, mint a jog, az orvostudomány vagy a tudományos kutatás nem feltétlenül képviseltetik magukat teljes mértékben.
Forrás(ok)

