A DeepSeek legújabb nyílt forráskódú AI modelljei a GPT-5 és a Gemini 3.0 Pro kihívásaként szállnak partra

Miután bevettük a a világot és 2025 januárjában az amerikai tőzsdéket is padlóra küldte, a DeepSeek most két új, nyílt forráskódú mesterséges intelligenciamodellt jelentett be: DeepSeek V3.2 és DeepSeek V3.2-Speciale.
A kiadás a vállalat határozott stratégiájának folytatását jelenti az AI fegyverkezési versenyben. Míg az OpenAI és a Google dollármilliárdokat ölt a számítási kapacitásokba, hogy betanítsák határmodelljeiket, és mindenáron a teljesítménynövekedést helyezték előtérbe, addig a DeepSeek más utat választott. Az előző R1 modellje azzal tűnt ki, hogy ügyes megerősítési technikák segítségével a GPT 4o és a Gemini 2.5 Pro teljesítményével azonos teljesítményt ért el, annak ellenére, hogy kevésbé fejlett chipeken képezték ki.
Túlszárnyalja a GPT-5-öt, miközben megfelel a Google Gemini 3 Pro-nak
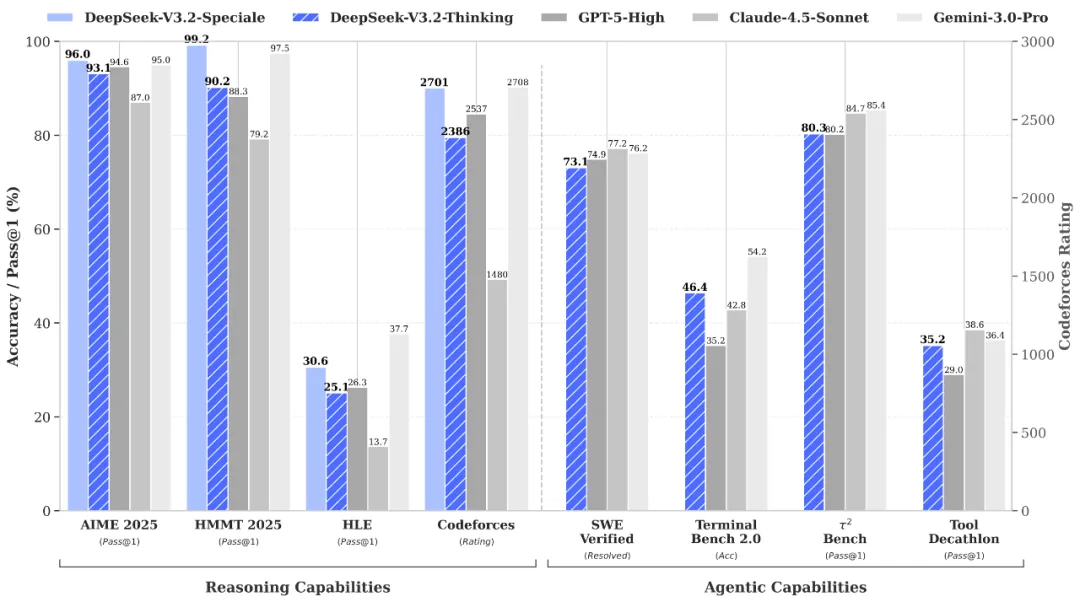
A standard DeepSeek-V3.2-t kiegyensúlyozott "mindennapi vezetőként" pozícionálják, összehangolva a hatékonyságot az ügynöki teljesítménnyel, amely a vállalat állítása szerint a GPT-5-höz hasonló. Ez az első DeepSeek modell, amely közvetlenül integrálja a gondolkodást az eszközhasználatba, és ez utóbbi mind gondolkodási, mind nem gondolkodási módban megengedett.
A DeepSeek V3.2-Speciale nagy számítási kapacitású változata azonban a címlapokra kerül. A DeepSeek állítása szerint a Speciale modell felülmúlja a GPT-5-öt, és a Google Gemini 3.0 Pro-val vetekszik a tiszta gondolkodási képességek terén. Sőt, a 2025-ös Nemzetközi Matematikai Olimpián (IMO) és a Nemzetközi Informatikai Olimpián (IOI) aranyérmes teljesítményt ért el. És hogy bebizonyítsa, hogy ez nem csak marketingfogás, a DeepSeek azt állítja, hogy közösségi ellenőrzés céljából közzétette az ezekre a versenyekre benyújtott végleges pályamunkáit.
A DeepSeek a teljesítménynövekedést a "DeepSeek Sparse Attention"-nek (DSA) tulajdonítja, egy olyan mechanizmusnak, amelyet a hosszú kontextusú forgatókönyvekben a számítási komplexitás csökkentésére terveztek, valamint egy skálázható megerősítő tanulási keretrendszernek.
A fejlesztők számára talán a legérdekesebb az ügynökökre való összpontosítás. A DeepSeek egy "nagyméretű ügynöki feladatszintetizáló csővezetéket" épített ki, hogy a modellt több mint 85 000 összetett utasításon képezze ki. Az eredmény egy olyan modell, amely képes a "gondolkodási" folyamatokat közvetlenül az eszközhasználati forgatókönyvekbe integrálni.
Elérhetőség
A DeepSeek V3.2 már elérhető a weben, a mobilalkalmazásokban és az API-ban. Eközben a V3.2 Speciale jelenleg csak API-ként érhető el, és egy szigorúan ideiglenes végponttal rendelkezik, amely 2025. december 15-én jár le. Emellett a Speciale egy tisztán következtető motor, és nem támogatja az eszközhívást. Ha szeretné ezeket a modelleket lokálisan futtatni, a vállalat részletes utasításokat ad ehhez a oldalon.